Build a Basic Web Scraper in Go
·
238 words
·
2 minutes read
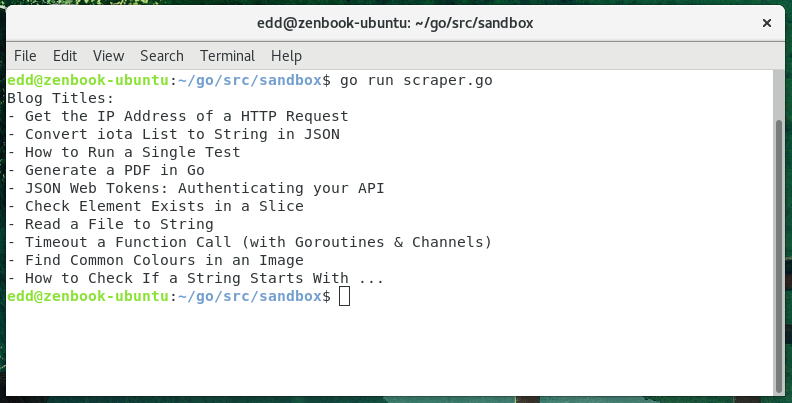
This is a single page web scraper, it uses the goquery library to parse the html and allow it to be queried easily (like jQuery). There is a Find method we can use to query for classes and ids in same way as a css selector. In our example we use this to get the latest blog titles from golangcode.
If you needed to search an entire site, you could implement a query to follow and recall a link urls.
|
|